关于如何理解Glibc堆管理器(Ⅰ——堆结构)
Last Update:
本篇实为个人笔记,可能存在些许错误;若各位师傅发现哪里存在错误,还望指正。感激不尽。
若有图片及文稿引用,将在本篇结尾处著名来源。
首先从 什么是堆 开始讲起吧。
在操作系统加载一个应用程序的时候,会为程序创建一个独立的进程,这个进程拥有着一套独立的内存结构。大致结构如下图:
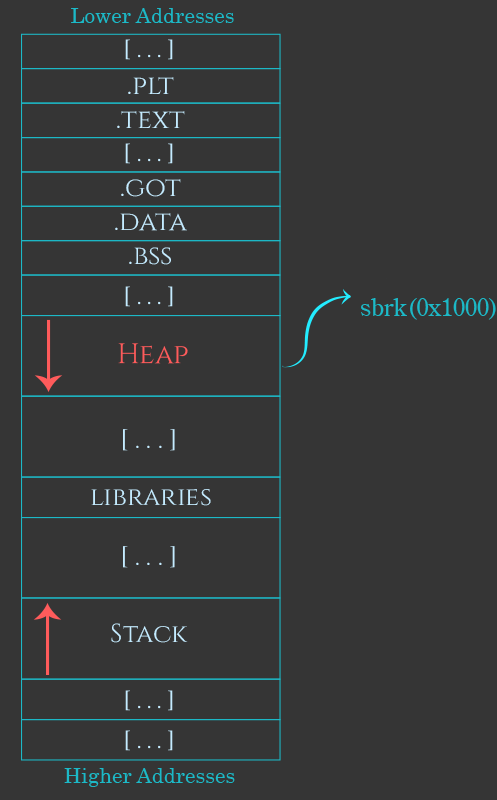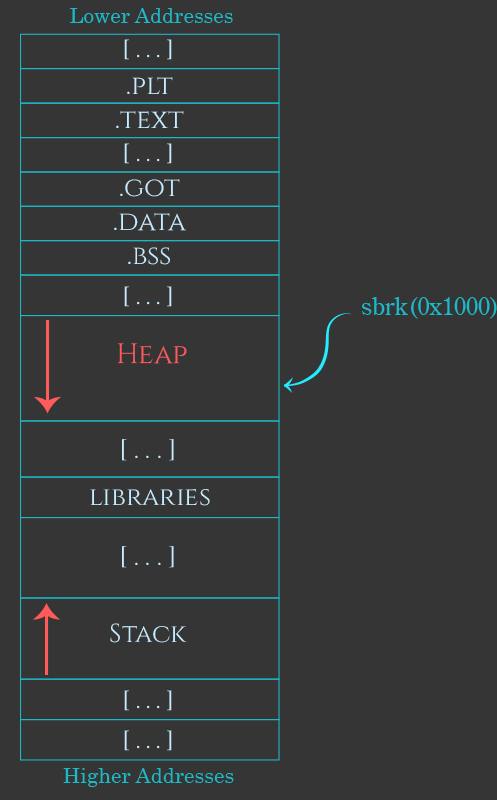
进程在运行之处会创建一块固定大小的堆空间,但当用户需要申请一块超出已有堆空间大小的内存时,操作系统就会调用**sbrk函数(也有其他类似功能的函数)**来延申这块空间
但正如我们所见,这样的拓展大小的方式似乎还是有极限的。当即便用sbrk去拓展Heap,也不能够满足用户的需求的时候(至少堆不能覆盖到栈上去,对吧?),操作系统就会使用mmap来为进程开辟额外的空间,这些空间可以被视为“虚拟内存”,它们不需要时刻都加载在内存中,因此能够大大提升堆的空间
当然,如果即便如此也不能够满足用户所需要的空间,那这个申请空间的操作就会失败,例如malloc,它会返回一个NULL
并且,上图还显示了堆在内存中的结构——一段连续的内存块,记住这个特点将对接下来的理解很有帮助
如下为一个堆的结构体申明:
1 | |
这可能会给人一种反直觉的印象,因为这个堆结构体似乎太小了,根本不能够像我们印象里的那样去存放数据
因此这里需要介绍一下Glibc中堆的寻址方式——隐式链表

尽管上图已经很详尽的介绍了堆的存放,但我仍然有必要多做些说明
操作系统会将堆划分成多个chunk以分配给程序,也就是malloc请求到的实则是一个chunk
而malloc返回的指针实则是指向**chunk+16(在x86中则是+8)**处的地址,究其原因就是因为结构体中的如下两项
1 | |
只有这两个数据是常驻于结构体中的(这句话有些晦涩,现在看不懂也没关系)
它们分别表示上一个chunk的大小和当前chunk的大小,那既然我们能够知道上一个chunk的大小,通过简单的加法就能够找到上一个chunk的位置了,这种方法就被称为隐式链表
而在mchunk_size的下面就是用来储存用户需要的数据
显然,如果从这个地方开始储存数据,上面给出的结构体就会被破坏了,因为另外四个成员无处安放了,但对于一个正被使用的chunk来说,这是无关紧要的,因此才说它们并不常驻(其中原因牵涉了其他,也将在下文叙述)
(但请注意,chunk块的申请是要符合**16字节(或8字节)**对齐的,尽管用户申请的时候看起来相当随意,但操作系统仍然会返回对齐后的堆结构)
同时,为了节省资源,mchunk_size的最后三位将用来储存额外的标志位,其意义这里不再赘述,但这里需要再一次强调的是,最后一位 P标记位 指示了上一个chunk是否处于被使用状态
尽管它们被用作标记,但在计算chunk大小的时候,我们会默认它们为0以计算合理大小
例如(二进制)1000101:Size=1000000,A=1,M=0,P=1
实际操作:
示范程序:
1 | |
通过如下命令去编译这个文件
1 | |
然后用gdb调试heap文件,我们将断点定在第11行,查看此时的堆
1 | |
可以看出,我们申请的chunk大小为0x80,但实际返回的chunk却有0x90(最后的1为标志位)
同时,它们是严格的按照堆的顺序往下开辟的,从0x602000到0x602090,没有其他空挡
而0x602120是则是被称为“Top chunk”的堆结构,在当前的堆仍然充足的时候,操作系统通过分割Top Chunk来提供malloc的服务
1 | |
而查看chunk1的内容,发现它指向0x602010而不是0x602000
这也作证了前面所说的内容,在这空挡的16字节中储存了常驻的那两个成员,而其他成员则被舍弃了
图片来源:https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/
插画ID:72077484