无壳,放入IDA自动跳到main函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 __int64 __fastcall main(int a1, char **a2, char **a3)
条件明确,要求我们输入的字符串和如下字符串相同
zer0pts{********CENSORED********}
提交flag发现错误,显然没有那么容易;观察函数列表:
从sub_610到sub_795的一系列函数笔记碍眼,不妨一个个看一下,能够发现sub_6EA有着明显的逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 __int64 __fastcall sub_6EA(__int64 a1, __int64 a2)
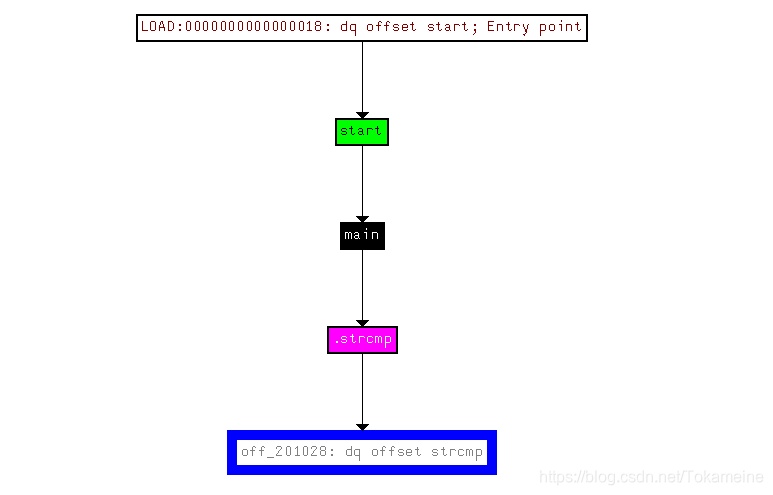
但当我试图用IDA查看该函数的交叉引用,会发现提示:
Couldn’t find any xrefs!
那这个函数岂不是没有被用到吗?不被执行还需要分析吗?
可以从init函数中找到答案:
1 2 3 4 5 6 7 8 9 10 11 12 13 void __fastcall init(unsigned int a1, __int64 a2, __int64 a3)
for循环中调用了一系列的函数,而函数地址从funcs_889开始,跟入便能够发现如下内容:
1 2 3 .init_array:0000000000200DE0 funcs_889 dq offset sub_6E0 ; DATA XREF: LOAD:00000000000000F8↑o
分别调用了sub_6E0和sub_795两个函数;上一个倒不值得关注,进入下面的那个看看:
1 2 3 4 5 6 7 8 9 10 // write access to const memory has been detected, the output may be wrong!
可见,off_201028被置为sub_6EA函数地址了
可以看到,off_2010288实际上是strcmp函数的地址,但现在它被替换成了sub_6EA
因此我们执行strcmp函数时实际上是执行sub_6EA函数
1 2 3 4 5 6 7 8 9 10 11 12 13 __int64 __fastcall sub_6EA(__int64 a1, __int64 a2)
逻辑:将字符串每8个比特位减去一个数字
1 .data:0000000000201060 qword_201060 dq 0, 410A4335494A0942h, 0B0EF2F50BE619F0h, 4F0A3A064A35282Bh
那么解密脚本姑且是能够写出来了
1 2 3 4 5 6 7 8 9 10 int main()
但是,我还是好奇这样一个字符串是如何实现大数加减法的,于是单步跟了进去
以 0x410A4335494A0942 为例,其二进制表达为:
100 0001 0000 1010 0100 0011 0011 0101 0100 1001 0100 1010 0000 1001 0100 0010
因为Intel是小端序的,所以从后面往前读
0100 0010——-> 66(十进制)
而我们的flag变换字符为:
‘*‘ (42)——–>’I’ (108)
相差正好为66;因此结果也变得显然了:
字符串大数相加的实现为:将大数做成多个字节,将每个字节与对应的字符串字符相加(指相同字节位对齐相加,多者溢出)
插图ID:90683044