封面ID : 89322214
前言:
笔者在学习制作软件外壳之前,一直对这种技术抱有过于简单的看法——即所谓的壳就是将代码段加密之后,往新节区写入解密代码并让OEP转为新节区处。
总体来说,这种解释并没有什么问题;但这种认识却是非常片面也过于简单的,以至于在实现的过程中接连发生了许多难以预料的问题。这些问题将在本篇下方逐一解释。
PE文件包括exe、dll、sys等多种类型,笔者只在这里实现EXE可执行文件的程序壳。尽管这相较于DLL文件更加简单,但也足矣说明很多问题了。
笔者会用代码和实操混合起来演示。
正文:
首先,先大致复习一下PE文件结构中一些和壳相关性较强的参数吧(详细定义不再赘述)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 WORD MZSignature;
还需要提一句的是,所有Windows系统下的PE文件,要想执行都需要经过“PE装载器” 来完成初始化和加载入内存的操作。这些PE文件结构中的参数就是做给装载器看的,只有确切告诉装载器一些数据,它才能将文件正确的加载入内存并完成一些其他的工作。
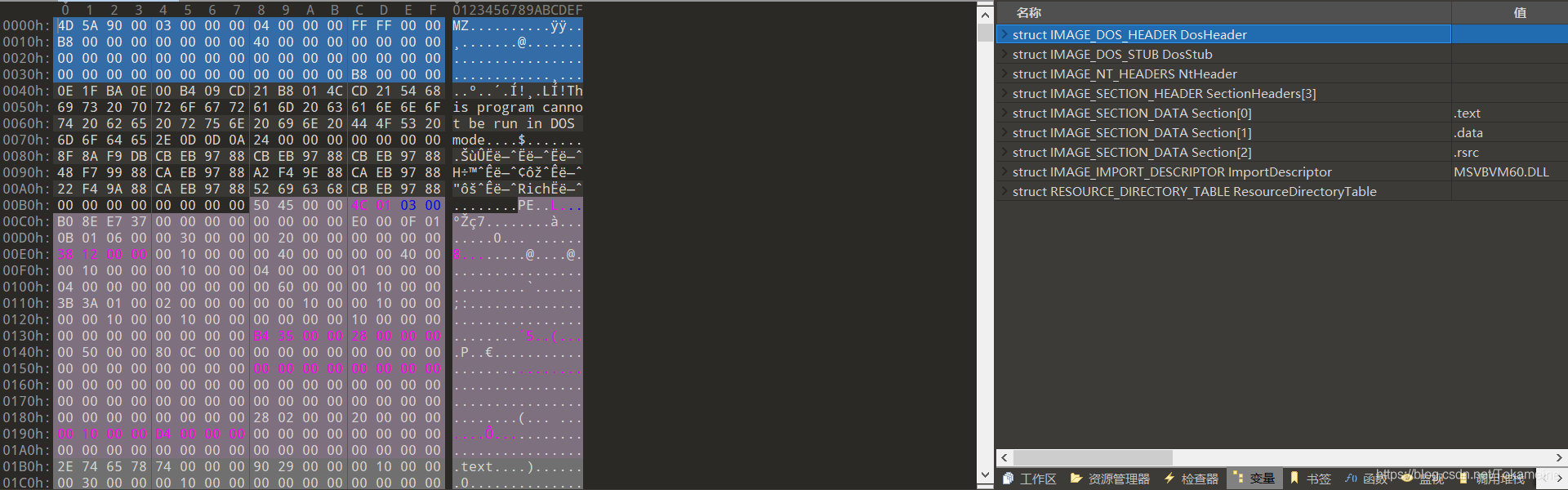
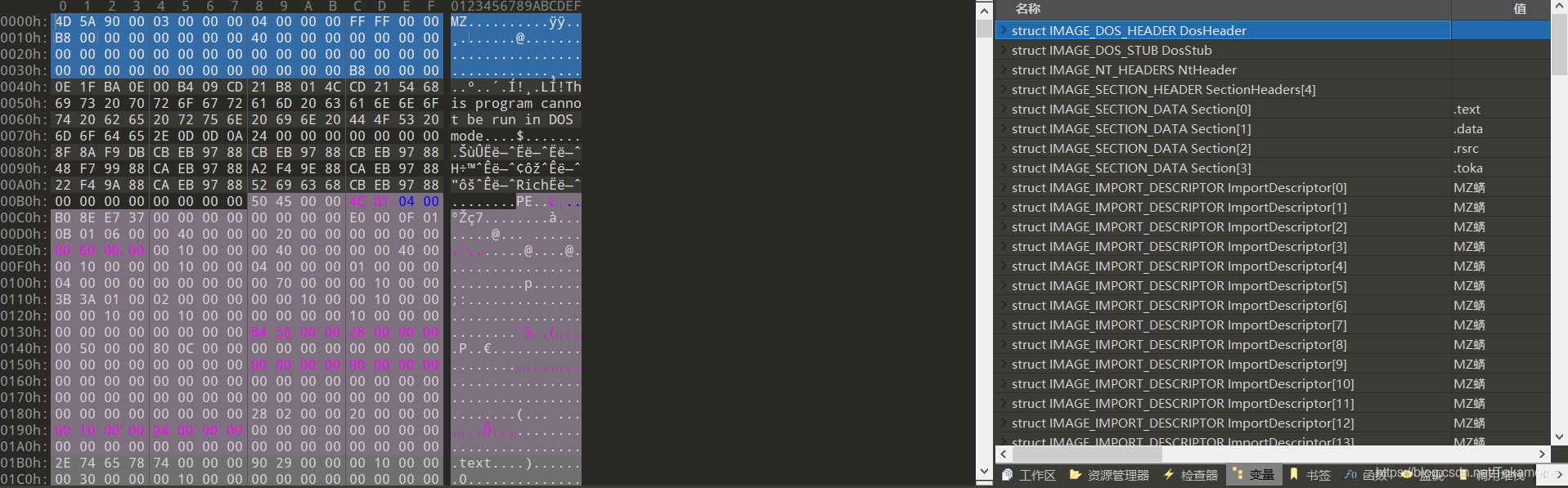
以下图程序为范例:
(这是一个比较特殊的范例,它只有三个节区 ,笔者为此碰了不少壁)
我们先走一遍基本流程,看看常规的操作是什么。
1 2 3 4 5 6 7 8 //读取待加壳文件
我将上面的三个变量设为全局变量以方便其他函数中也能够调用,通过WindowsApi里的函数实现映射,此时,lpBase将指向文件的开头(MZ签名)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 //验证该文件是否为PE文件
笔者一度以为这种验证方法是否有些拘谨,但这一部分在实际操作中并不会有什么问题,因为PE装载器也是这样来识别文件的;这意味着,那些压缩文件头的壳即便将文件头修改得面目全非,也仍然能被识别成PE文件,因此多种壳的嵌套似乎就并没有那么不可能了。
1 2 3 4 5 6 //声明一个指向“新节区头”的指针pTmpSec
节区头是一个固定宽度的结构体,在“windows.h”中可以通过PIMAGE_SECTION_HEADER 来直接声明(该文件头也包括一系列的PE文件头结构)。
而按照PE文件的结构,Nt头的下面就是节区头,代码逻辑已经足够清晰了便不再赘述。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 typedef struct _IMAGE_SECTION_HEADER {
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 /*初始化“新节区头”的各项参数*/
Name 是一个8Byte字符数组,可直接拷贝。
VirtualAddress 为节区加载如内存时的RVA ,它应该符合SectionAlignment 的对齐参数(例如 .text的VirAddr为1000h,下一个节区的大小就应该是 (VirAddr+SizeOfRawData)的向上取SectionAlignment的整数倍)
而SizeOfRawData 则也该符合FileAlignment 整数倍向上取整对齐
我们默认新节区中存放的内容均可被当作代码执行,因此SizeOfCode 增加节区的SizeOfRawData 大小
节区属性通常是固定的值,暂时不需要考虑过多
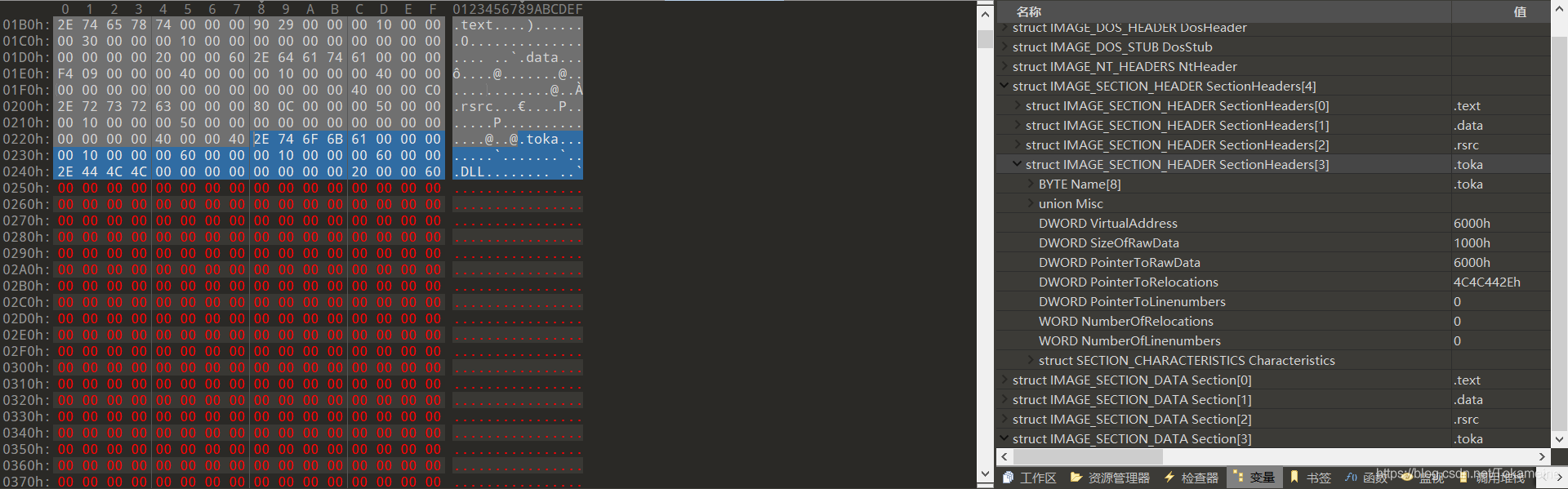
最后将Nt头中的SizeOfImage 增加节区的VirtualSize 大小,并保存当前的OEP,将OEP设置到新的节区,完成一个新节区头的初始化(下图为此时的文件状态,可以看见,010已经能够识别到新的节区头和新的节区位置了)
那么接下来,我们就需要给这个尚且什么都没有的节区添加可执行代码了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 char shellcode[] =
申请一段空间,大小为 节区大小-shellcode 大小,并将内容置零
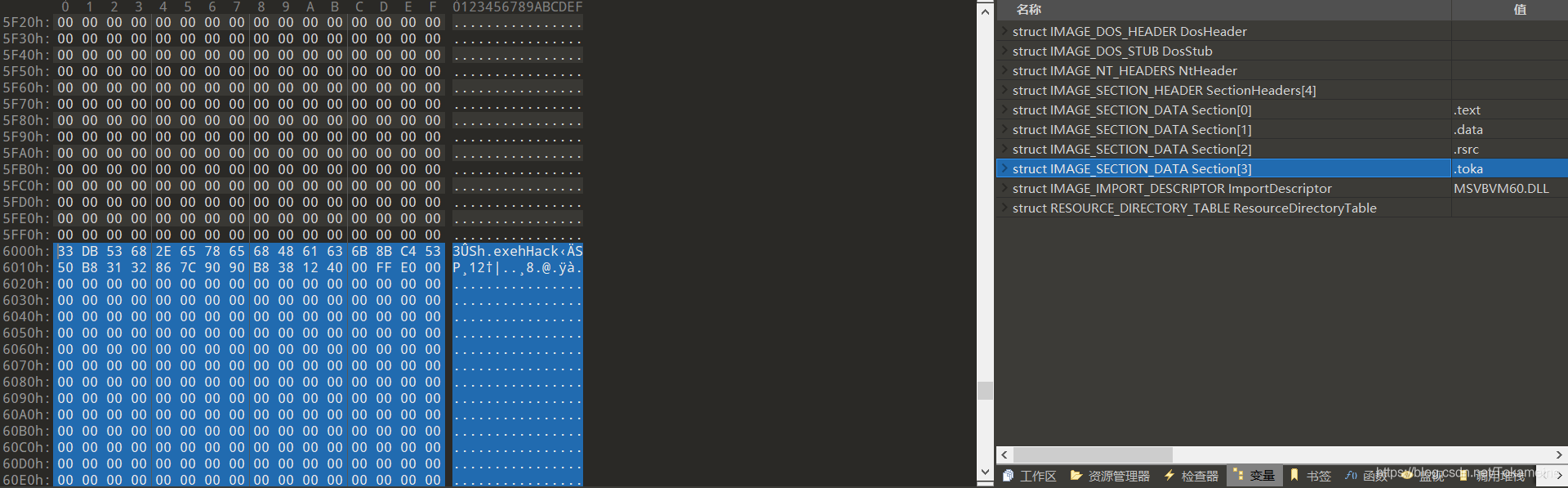
向文件末尾写入shellcode ,并多余补零将节区大小不充到之前设定好的SizeOfRawData
可以看见,新的节区也已经获得了数据,倘若现在将其放入Ollydbg中动态调试,我们将得到预期的结果,并且软件也能够正常运行。
倘若我们只需要一个“伪壳” ,那么做到这一步已经足够了;但实际上,上面的操作和基础的Shellcode注入并没有什么不同 。它远无法达到一个“壳”所要求的强度
因此我们需要为它引入一个“代码加密模块” ,只要没有运行完壳代码,源程序将无法运行(这里将只加密 .text 段)。但一旦加密,许许多多的问题就跟着来了。
1 2 3 4 5 6 7 8 9 //异或加密
在添加节区之后,我们为代码增加这样一个模块。它将会把**.text段的每个Byte与0x0D异或**
那么来看看这样做会导致什么问题吧
可以发现,010的识别出现了严重的偏差,但这个问题似乎还不够具有冲击力,不妨试着放入Ollydbg动态调试一下?
可能你会好奇,我还没有写如解密的代码,不能运行难道不是很正常吗?
但再回忆一下刚才的过程,程序的OEP应该是我们自己编写的Shellcode,它是没有经过加密的;也就是说,哪怕程序不能运行,它至少也应该能够执行到Shellcode结束的地方 才对吧?
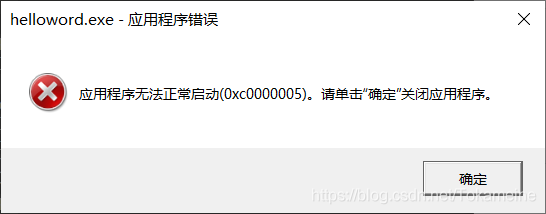
再来看看这个错误**”0x0000005”**,常见原因为内存地址非法引用、越界等,从结论来说,因为内存的错误导致程序已经完全不能运行了(程序已损坏)
那么接下来讨论一下这个问题的原因:
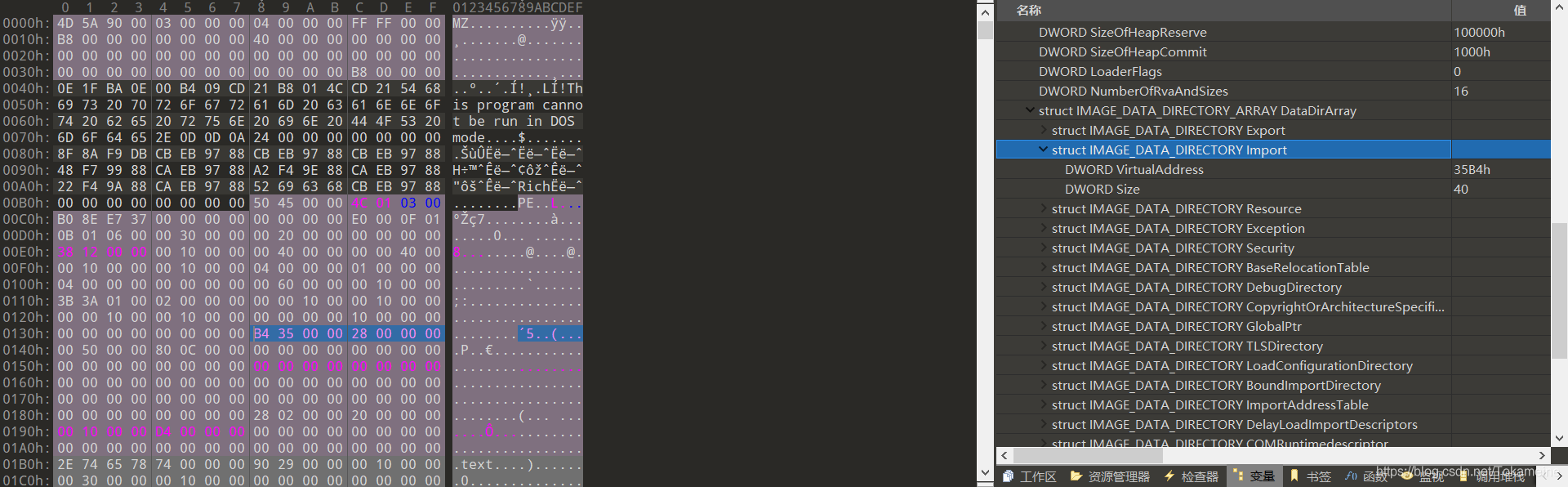
我们需要引入一个上面没有提到的概念——“导入表”,它就在OptionalHeader 中的DataDirArray 里
下图为导入表完整的结构顺序,方框代表结构体,文字表示一个地址
1 2 3 4 typedef struct _IMAGE_DATA_DIRECTORY {
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 typedef struct _IMAGE_IMPORT_DESCRIPTOR {
1 2 3 4 5 6 7 8 9 typedef struct _IMAGE_THUNK_DATA32 {
1 2 3 4 typedef struct _IMAGE_IMPORT_BY_NAME {
当系统运行PE文件时,装载器将会通过这张导入表的IMAGE_IMPORT_BY_NAME 来得知程序需要用到哪些外置函数,并将这些函数的地址写入FirstThunk(IAT),于是你的程序就能够通过调用 FirstThunk 中储存的地址来调用函数
那么,这些导入表被放在示范文件的哪些地方了? .text 段
所以原因也就清楚了,当装载器试图获取函数的时候,你告诉它的每一个地址都是错误的,程序自然就会因为错误的地址导致崩溃了
所以,如果你尝试将IMAGE_DATA_DIRECTORY 中的Size 置零,或是将VirtualAddress 置零,还或者是将IMAGE_IMPORT_DESCRIPTOR 置零,你的程序都不会发生刚才的问题
放入Ollydbg中就能发现,程序至少能够执行到shellcode处了
但实际上,我们其是遇到的不应该是这样的程序
上图为win7操作系统自带的计算器calc.exe
我们可以很明显的发现,它的导入表全都在 .rdata ,这完美的避开了导入表被破坏的情况
因此倘若我们对这个文件进行加壳的时候就不会出现因为导入表破坏的情况出现了
后话:
这更像是一种偷懒的方式,因为我们不可能总能遇到这张刚刚好的程序(尽管版本较新的编译器都会把这些段明确区分开来了)。
笔者查阅了各种各样的文章,最终只在思路上有所理解,却苦于实现有些困难
《加密与解密》第19章给出了导入表抹去的一种思路:
通过拷贝原导入表并抹去,将导入表写入新节区;在壳代码段中调用LoadLibray()与GetProcAddress()两个函数来模拟装载器生成导入表的操作,最后将获取的地址装回原导入表的IAT处实现表的重载和加密。
但我翻阅了一些大佬的文章,均没有提及上述过程的具体流程,似乎都默认了IAT不会被加密这一事实,因此在这里留作一个疑问,哪天得到了答案再作补充吧。
至于Shellcode的构造,这里不做赘述,笔者自己目前也并没有非常精通,还是不要误导他人为好。
参考 :
《加密与解密》
九阳道人:
https://bbs.pediy.com/thread-250960.htm
https://bbs.pediy.com/thread-251267.htm