我们对 PWN 都有哪些误会
Last Update:
应安恒的邀请,笔者撰写了本文。希望它能帮到那些想要入门 PWN ,却又不知如何是好的新人。
前言
刚入学的时候问了一些大哥们 CTF 中都有哪些方向,分别是做什么的,以及难易度如何,对于难易度方面,大哥们基本上都会回答 “PWN” 是入门最困难的方向。这对于当时一无所知的我造成了巨大的心理压力,但由于队内基本上没有其他师傅做这个方向,所以最开始是半推半就的选择了它。
但是它其实并没有人们说的那么困难,只是因为人们对他的印象与其他方向相比,更具有一层朦胧感。比如 Crypto,一言蔽之其实是数学;再比如 Web,入门其实是各种工具的使用;但到了二进制方向,我们发现,其实不太好找到一个简单易懂的描述去向新人说明它的入门门槛是什么,无论怎么说,似乎都有一些薄薄的朦胧感。
就比如我向你介绍 Pwn 的时候说它是 “二进制漏洞挖掘与利用”,并跟你说 “先把 C 语言、汇编、CSAPP 看完”,假设你是一个刚入学的大一新生,并且从来没有接触过这方面的相关内容, 那你大概率只能听懂 “先把 C 语言看完” 这一点,相比于 “先把某某某工具的使用熟悉一下” ,然后大哥紧跟着丢了几篇简单易懂的操作教程,自然还是 Pwn 比较令人迷糊。
但事实上,如果你是计算机相关专业的学生,那 Pwn 的前置技能其实很可能是你大学三年的必修课,只是你需要提前把它们掌握罢了。哪怕你的培养方案里没有这部分内容,甚至哪怕你不准备做 Pwn 方向,掌握一部分基础技能也会让你对计算机的理解更加深刻(甚至你会发现,渐渐的,你的理解已经让同学无法理解了)。
所以 Pwn 其实并没有人们常说的那样难以入门,因为很多内容都是你的必修课而非专业课,只是你需要靠自学的方式提前把它们掌握罢了。
不过我对 Pwn 的态度正如我过去在知乎的某个回答:
个人感觉最大的难点在于“能否耐得住寂寞”,因为很难说一个人会对这个东西长期持续地抱有很高的热情,大概是有那样的人,并且那样的人都成大神了,但我这种普通人说实话不太做得到……兴趣肯定还是有的,但很难说还会比当年刚入坑时候要高了。
个人认为现在学pwn已经没有什么系不系统的问题了,随便一搜资料,跟着大师傅们做做,入了这个门槛,然后从此以后基本上自己就能知道要做什么了。但难点在于,现在是2022年,前人搞过的东西已经被修缮的非常好了,但你还是要从前人的路开始走,因此很可能会有一段很长的时间是“什么都做不了”的状态,比赛也是爆零,挖洞也什么都不知道,像是浑浑噩噩就这么晃悠过去一两年之类的,然后就渐渐没有了当年的兴致,觉得这条路太过艰难了(我自己就是这种菜鸡,有很长一段时间因为和现在的赛题考点脱节以至于比赛一题都做不出来…),然后再看看同级的师傅们去搞钱,一两天就赚的比自己实习一个月还高,眼一红心一横就转 web 去了,然后靠着二进制基础比别人多拿一点……
我必须在刚入门时抱以极高的热情,才能在漫长的自学过程中坚持下来,否则这很容易就让人怀疑自己是否需要如此急迫的完成如此之多的任务,但实际上,这却又是没办法的事情。
How to do
Q1:到底什么时候才算入门
不妨先枚举一下常被归为入门必修课的技能:
- 提问的智慧
- 搜索引擎的使用
- C 语言
- 汇编语言
- IDA/gdb 的使用
- Python 脚本的编写
- x86_64 架构下程序运行原理
- ctf-wiki
其中最容易被忽略,却又最重要的其实是第一和第二个。只有先学会如何提问和如何自行解决问题以后才有其他后话可说。当然,大部分人都会在之后的学习里不知不觉地掌握它们,但首先得有这份意识。
然后是二进制精专的入门课程,想来很多人在初学时都会跟我一样抱有这样的疑问:“我知道要学这个,但是要学到什么程度才行?”
其实这并不需要自己去烦恼,因为我们最后都要进入实战。当你困惑于是否还需要继续向下深入时,不妨上更大平台找一道入门题目,在不看任何答案的情况下检验自己。如果你能够做出来,哪怕只是勉强做出来,那都说明你已经迈过了这个门槛。而如果你尚且还做不出来,那么就需要了解自己是因为哪方面的原因导致,然后在这个方面进一步深入。
比方说 C 语言,但你看完了基础语法,能够上手写点简单的代码时,就可以开始尝试了;再比方说汇编,如果你能一行一行读明白它们在做什么,那大多时候也足够入门了。
用具体的数值量化的话,如果你看的是书籍,那么一般要看到书的 1/2 部分,剩下的 1/2 或许暂时用不上,但日后总会遇到需要补课的时候。
总的来说,只要能够独立完成一道基本的 ret2text ,其实就已经算是入门了。
Q2:我学完了基础,为什么感觉看题时还是很迷茫
一般来说也分两种情况,一种是遇到了自己从没见识过的东西,另外一种则是基础不够扎实。这里推荐各位参考 CTF-Wiki 下 Pwn - Linux Platform - User Mode - Exploitation - Stack Overflow - x86 部分,跟着其内容完成 栈介绍-栈溢出原理 - 基本 ROP 这三个部分。在你完成这三个部分以后,基本上对于常规的栈溢出入门题来说,哪怕不会做,也不至于看不懂题目想让你做什么了。
对于一些因为没接触过的提醒导致的迷茫,最好的办法就是搜索。刚入门的时候大家都只接触过栈溢出的利用,但是一旦突然撞上了堆题,那一头雾水也是再正常不过的事情了。这种情况下最好的办法就是现学现用,活用自己的搜索能力去寻找于题型类似的题目,如果找不到,再开始从头学起。
这里介绍一些常规的做题流程,具体细节可能因人而异:
- 确认题目的运行环境 - 运行的平台/动态库版本等
目前的大环境来说,对于需要使用 libc 的题目一般都会将使用的 libc 或者容器的 dockerfile 作为附件一起打包给选手。对于前者的情况下,当我们直接使用 IDA 打开该文件即可知道对应的版本:
如果题目需要选手直接对堆进行调试的话,那么就需要使用 Glibc-All-in-one 和 patchelf 根据版本去修改链接的动态库。
这里推荐一下团队里的师傅开发的工具:https://github.com/ef4tless/xclibc.git,该工具能够一键完成上述的替换功能。由于 README 写的非常完善了,这里就不过多赘述。
而如果题目附件中提供了 dockerfile,那么使用的动态库版本一般都会和使用的容器一一对应。
1 | |
对于大多数 dockerfile 都会在第一行标注出使用的容器环境,对应关系如下:
- ubuntu:16.04 / glibc-2.23
- ubuntu:18.04 / glibc-2.28
- ubuntu:20.04 / glibc-2.31
- ubuntu:22.04 / glibc-2.34
除此之外,最新版的 glibc 已经到了 glibc-2.38 了,但这之后的版本使用范围比较小,目前大部分都只会用到 2.34 版本为止。另外,如果选手遇到一些使用特殊版本的容器时,就需要本地构建 docker 容器后将动态库从容器中复制到本地。具体要根据题目给出的构建规则去创建容器,然后使用类似如下的命令拉取:
1 | |
另外,对于一些跨架构的题目,比如 arm64 等,则需要使用 qemu 去模逆执行,具体情况要根据题目去选择。
- 反编译二进制文件静态分析理解代码逻辑
接下来我们用一道具体的题目来练练手。
这里笔者选用了今年举办的 CISCN 初赛中的 shaokao 作为演示,考虑到部分师傅可能对计算机原理还不甚熟悉,因此只选用了较为入门的一道题目。
因为文件不是很大,我们先用 IDA 直接打开它,看看能不能做些简单的分析:

部分师傅用 IDA 打开以后可能直接反编译不会是这个结果,这种情况下请使用 IDA7.7 以上的版本,其中添加了对 switch 的反编译支持
可以看出,题目是一个基本的菜单,根据用户输入的内容分别有几种不同的函数被执行,接下来我们一个一个跟进去确认一下
case1
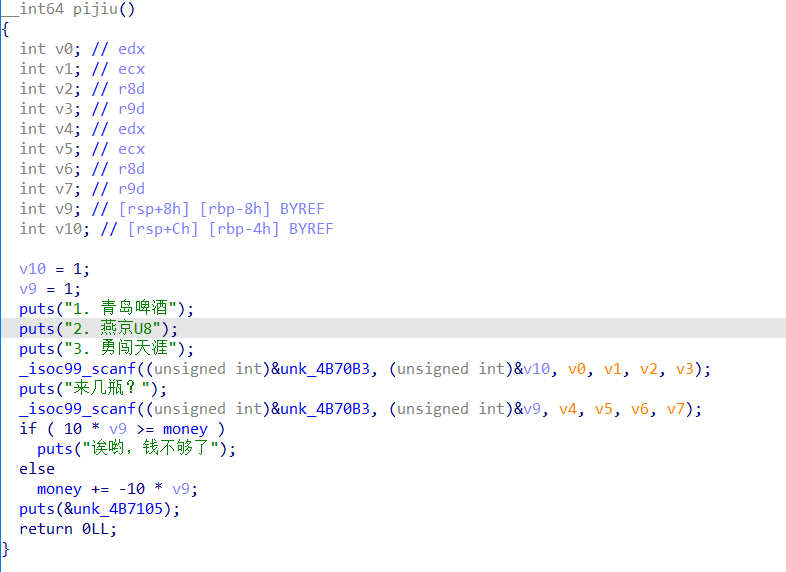
代码还算清楚,可以看出第一个函数是用来购买啤酒的。用户先是选择想要的种类,然后给出数量,最后会将全局变量里的钱进行扣除
case2
分支2 和前一个函数基本相同,基本上只有价格不一样而已,所以这里我们快速阅读后可以跳过这个函数。
case3

这个函数用来显示当前还有多少钱,写的很规范,基本上一眼就能排处它的嫌疑
case4
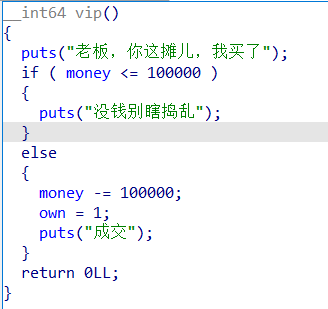
分支4的逻辑也很清晰,如果我们现在非常有钱,那么就能直接把烧烤摊买下来,这里设置了 own 为 1,在 main 函数中我们可以看到,如果这个全局变量非 0 ,那么我们就能够进入分支 5
case5
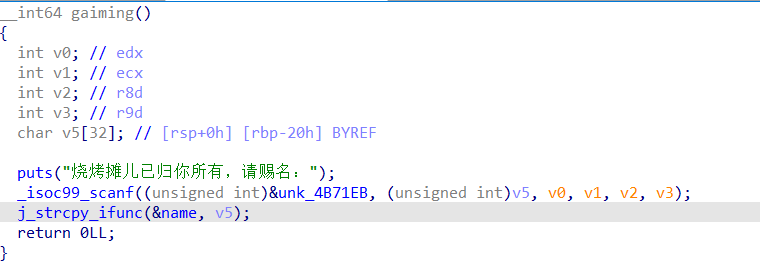
此处可以见到另外一个输入函数,而 scanf 函数作为一个读取输入的函数,根据参数的不同是有可能导致危险的。通过 IDA,我们可以确认出它所使用的格式化字符串为 %s ,这意味着此处存在栈溢出漏洞。
漏洞发现与利用
到这一步相信读者已经大概明白要怎么完成这道题了。题目的逻辑很简单,当用户的钱非常多的时候,就可以把烧烤摊买下来;而买下来以后就可以调用 gaiming 函数触发栈溢出写入 ROP 来劫持程序的运行了。
如果您对 ROP 的工作原理感到困惑,可以阅读本文:https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/stackoverflow-basic/
但是问题来了,这个 money 的默认值是 233,而且我们似乎不管做什么都只会减少不会增多,那要如何才能买下烧烤摊呢?
如果您已经知道了整数溢出漏洞的存在,那么想必您已经知道对于计算机来说,加一个数等于减去一个负数,只需要买 -10000 瓶酒就能搞定了。
但是假如我们作为一个刚刚入门的新人,才只接触过栈溢出的基本利用,此时正是一头雾水的时候,我们该怎么办呢?
那么此时肯定就要依靠我们自己的搜索和整理能力了。第一个方法很简单也很朴素,既然是我们从未了解过的漏洞类型,那么遍历一遍常见的漏洞列表,大概率能找到与之吻合的类型:
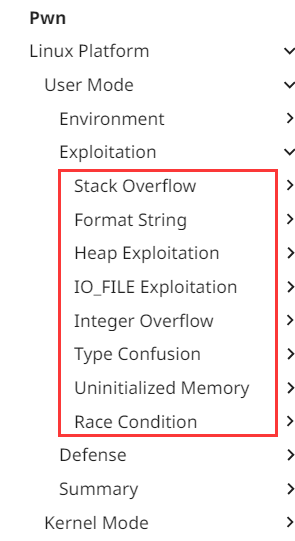
排处掉第一个栈溢出之后,第二个是格式化字符串。再确认了所有的 printf 和 scanf 的输入参数都不能由我们控制后,这个类型也可以排处。以及由于整个程序都没有使用到 malloc 和 free,肯定和堆也没关系,因此也排除第三种。
第四种看起来非常的复杂,对于新人来说基本上完全看不懂,因此暂且跳过。当我们选到第五种的时候,联系其逻辑中对全局变量的运算,就能相对自然的把利用方式对上。
- 动态调试验证漏洞存在
而既然我们现在模模糊糊的确认代码中存在整数溢出,那么接下来就是要通过调试来确定这个漏洞的存在了。
我们写一个简单的脚本去验证一下:
1 | |
脚本的逻辑很简单,随便选一个啤酒,然后买上 -999998 瓶,然后来看看 gdb 里的反应如何。
我们在这个地方下了个断点,观察一下什么值会被放入全局变量:

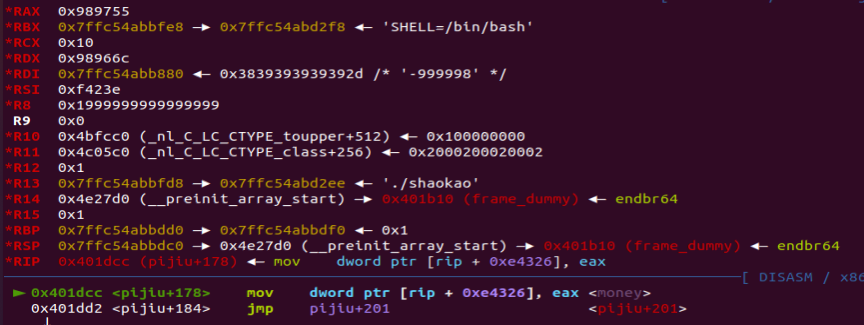
通过调试可以发现,此时的 eax 真的会变成一个非常大的数字,从而我们验证了漏洞的存在,现在就可以开始编写 exp 了。
- 编写脚本+调试进行利用
由于题目是静态编译的,因此我们可以使用如下命令快速构造 ROP
1 | |
最后构造的 exp 如下:
1 | |
整个过程一般来说没有什么可以取巧的地方,但在编写脚本时可以提前自己准备好一份框架模板,在用的时候只需要修改文件名就能直接上手,这会避免些许时间浪费。
比如这样,提前将要用到的函数简化等:
1 | |
总结
总的来说,这道题目并不困难,笔者相信对大多数师傅来说都是非常简单的一道题。但是本文既然面向即将开始入门这个方向的师傅,如果全文都是在讲述极其复杂的理解和利用,相信这会让大多数人望而却步。如果您真的期望看一些较为复杂的内容,籍此提前了解一下未来会遇到哪些麻烦的问题,欢迎您浏览笔者的博客和某些论坛的主页。
归根结底,笔者在此还算希望能减轻师傅们对 PWN 的一些畏难心理。因为笔者最开始学 PWN 的时候也会因为见到不认识的内容感到无从下手,从而放弃整道题目,而在事后看完 writeup 又觉得追悔莫及。
Q3:学习过程中有没有什么重难点需要注意?
学 Pwn 最忌讳的就是“怕麻烦”。很多时候可能看反编译出来的伪代码难以理解,但其实上手调试一下就能解决。而克服自己怕麻烦的心态其实就是 Pwn 的成长路途上几大麻烦之一。
另外一个点则是“有耐心”。尤其是对于刚入门不久的师傅们来说,Pwn 的做题流程相比于其他方向都显得更加的冗长,有的时候连第一步的环境搭建都要折腾上几个小时之久,还会面临各种各样极其麻烦的场景,因此对 Pwn 手来说,耐心是一个很关键的要素,一方面在做题时保持心态才能够稳定输出,另一方面只有长期保持兴趣才能在 Pwn 的道路上越走越远。
除此之外,在技术上的重难点就是对技术的适应性。随着现在 CTF 比赛越来越多,题型和技术栈也是越来越繁茂了,如何在遇到新型的题目设计时尽快适应也是一个重难点。举个简单的例子,对于做惯了 x86_64 下 C 语言赛题的师傅,如果突然给出了一道 arm64 Pwn 的题目,又或者是 Rust 编写的题目时,如何快速的适应题目并展开分析就变得重要了。
以我的个人经验来说,要想快速适应新的题型,往往需要通过大量的赛前积累。这并不意味着靠题海战术解决,而是通过不同的类型赛题去培养自己的直觉,养成了一个良好的意识习惯以后,自然就对各类题型都不会觉得梗塞了。
以 Arm64 架构举例:做惯了 x86_64 架构的师傅都知道,x86_64 是基于栈和寄存器的架构,这意味着栈溢出能够劫持它的运行逻辑。现在我们切换到 arm64 ,通过资料可以查阅出,它是一款基于寄存器的架构。在 x64 下,call 一个函数时会将返回地址入栈,而 arm64 肯定也要具备函数调用的能力,那么它的函数调用是如何实现的?
通过搜索可以找到如下样例:
1 | |
可以发现它使用了 x29 和 x30 两个寄存器,再往下查找资料可以发现而这分别用于储存栈帧和返回地址。而在嵌套式调用中,调用以前会将当前函数的返回地址和栈帧入栈,这就相当于 x64 下的 push rbp;push rip+8 了,因此栈溢出对它仍然适用,只是覆盖的返回地址不能够立即劫持,需要等待当前函数返回后,将劫持的返回地址加载到 x30,并且当父函数再次返回时才能够劫持。以及中间需要选择其他 gadget 对栈进行维护从而构造 ROP 进行持续控制。
此处,笔者所说的 “直觉” 其实指的就是在遇到该架构时能够先考虑到理解函数调用和栈的关系这一点,从此处开始向下搜索资料来完善自己的猜测,最后验证猜测。
当然直觉也是失灵的时候,在失灵时能够尽快提出另一种可能性也是一种灵活。
Q4:有哪些值得推荐的书籍或网站?
书单
首先先推荐一下这个项目:https://github.com/olist213/Information_Security_Books,里面基本上涵盖了每个方向的相关书籍,读者可以按需自取。
然后是笔者为 Pwn 师傅们推荐的单独目录:
- 操作系统(B):《操作系统真象还原》《鸟哥的Linux私房菜》
- 计算机原理(B):《深入理解计算机系统(CSAPP)》,《程序员的自我修养》
- C/C++ (A):《C Primer plus》《C++ Primer plus》
- 汇编语言(A):《汇编语言》- 王爽
- 数据结构(C-):《数据结构与算法分析 —— C语言描述》
- 网络协议(C):《TCP/IP 详解 (卷一)》
- 逆向工程(D):《逆向工程核心原理》
- 编译原理(D):《编译原理(龙书)》
操作系统是每位 Pwner 必备的基础知识,哪怕不准备往内核方向发展,这两部书也是有必要看的,其中第一本能在极大程度上驱散自己对计算机核心的心中迷雾。而第二本则是辅助,如果有时间可以看看。
计算机原理则是另外一部分必要内容,CSAPP 不要求全都看完,个人认为看到 11 章就非常足够了,而 Lab 只需要做到 Lab4 就能在很大程度上满足需求了。当然,如果有时间,自然是越多越好。而《程序员的自我修养》则在另外一个方面弥补自己对软件构建方面的缺陷,这本书不厚,很快就能看完,但非常推荐去看看。
C/C++ 则是必要的语言基础,我个人认为,C 语言一定要学好,而其他语言的最低限度是能够会看即可。由于大部分语言都有自己的语义结构,因此从字面上理解往往并没有那么困难,我个人认为对于其他语言可以浅尝辄止,但 C 语言一定要学的足够深。
数据结构部分其实并不是那么关键,尽管几乎所有计算机类都会有这么一门必修课,但实际上用到的机会并不是那么多。但我仍然推荐各位对此稍微有些了解,因为数据结构中的很多实现往往较为晦涩,如果没有自己编写类似代码的经验,在对此类题目进行逆向分析时会吃上些许苦头。
网络协议部分也是较为关键的内容,因为 Pwn 的目标在现实场景下其实涉及到网络组件的情况更多,掌握这部分知识会让分析代码的过程更丝滑。
逆向工程和编译原理相对来要求没那么高,在已经完成了前面所说的部分以后如果仍有余裕,可以考虑这部分内容作为额外的提升。
至于阅读顺序,个人是建议按照上述目录标准的顺序,从 A-D 递减的优先级进行阅读。
练习
- CTF-wiki : https://ctf-wiki.org/pwn/linux/user-mode/environment/
- BUUOJ:https://buuoj.cn/
对大多数人来说,CTF-wiki 可以解决入门阶段 90% 的基础,而 BUUOJ 和一些其他的练习平台作为辅助,闲暇的时候刷上一两题巩固基础,提高熟练度。
就我个人而已,我更推荐以赛促学,练习更多的只是平常用于巩固,刷上 2-3 页其实就很多了。更加高效的方法是参加一些难度并没有那么高的比赛,在那种连续的环境下长时间思考能够快速提高自己的技术水平。比如说安恒的月赛、各大高校的新生赛,都是不错的选择。
Q5:如果我要学 Pwn ,有没有什么建议?
Pwn 其实是一门较为综合的方向,它的实际范围其实要比我们在比赛中能够遇见的更广,这决定了它注定不是一条轻松的路。二进制安全的历史其实非常久远,很多东西已经非常完善了。比方说现在的 Rust 语言就在很大程度上解决了内存安全问题,所以它越是发展,我们就越是没事做。安全行业的实质是在消灭安全行业,所以为了求生,除了比赛相关的内容以外,也建议师傅们对自己设立一些更高的目标。
学 Pwn 的目的不只是为了在比赛里能拿个好成绩,更不应该是因为队伍里没人学所以自己补个位,认清楚自己的目标,提前想好自己在未来能够用它做些什么才是更重要的事情。
实践经历
Q1:理论与现实的差距在哪?
仅限于 Pwn 方向来说,CTF 和实际的工作内容的差距是非常大的。从最基本的性质上说,CTF 的本质是 Game,Game 就肯定有通关的方法,也就是说题目必然是有解的,但现实里挖洞却不一样,有的时候它可能真的没洞,又有的时候或许漏洞过于隐蔽以至于自己无法判断是否能够挖出。
我相信大多数师傅在做题的时候都很少会接触到超过 1mb 大小的 Pwn 题,现在因为 Rust 和 Golang 等语言的出现,二进制文件可能相比以前的 C 语言大上不少,但一般都不会超过 10mb(排除静态编译的情况)。但在真正的工作里,我们有可能要面对远大于这个量级的样本,可能一个样本有 20mb 甚至更大,函数的数量超过十万个,在这种条件下,按照做 Pwn 题的方式去分析样本几乎是不可能完成的任务。
也有一些相对苛刻的情况,可能做过 IOT 的师傅会更清楚,模拟设备和真实设备的差距是很大的,对于一些特殊设备可能根本没办法进行模拟,这就更加麻烦了。
Q2:那我该怎么办呢?
正如上文所说的,拓宽自己的技能栈。Pwn 的总体方向是 “二进制漏洞挖掘与利用”,其中包括了挖掘部分。CTF 中其实有意削弱了这漏洞挖掘的部分,因为对于限时的比赛而言,挖洞往往耗费大量的时间且并不体现选手的能力,因为有的时候,能否挖出漏洞甚至是一个运气问题。
那么弥补这部分靠 CTF 无法学到的知识就可以了。常用的漏洞挖掘的方案一般包括黑盒测试、灰盒测试和白盒测试,掌握这方面的技巧,参考一些比较经典的项目,比如 AFLFuzzer、Codeql 等,能够在很大程度上弥补这方面知识。
当然,最终都要落到实处。尝试着去找一些相对简单的项目进行真正的漏洞挖掘,亲身体验一下那种过程要远好于各种资料。
如果在过程中遇到了自己难以解决的问题,比起自己埋头硬干,也建议各位师傅积极与其他师傅交流,各大比赛的官方群在赛后其实都是不错的交流平台,以及一些 Pwner 交流群和各大论坛都能提供一定的帮助。
结语
不知道各位有没有发现,我似乎总是倾向于用文字而非图片或其他形式进行表达。
由于我在编写文档时总是习惯用 markdown 这种标记语言进行编辑,这种文档显示出来的效果会因不同的编辑器而异,所以尽管 Obsidian 的风格非常优雅,但为了兼容性考虑,我还是在大多数时候避免使用表格和图片,后者主要是因为图片的非常耗时。出于种种考虑,如果您希望以一种快捷的方式撰写文档,我也推荐您使用 markdown 代替 word 文档。
最后再贴个自己的小博客:tokameine.top